
Prompt engineering and AI prompt writing are skills that improve only through testing. You can read every guide on the planet about crafting the perfect ChatGPT prompts, but until you actually run your prompt, evaluate the AI response quality, and iterate, you're guessing. The difference between a mediocre prompt and a high-performing one often comes down to three or four refinement cycles.
Most power users skip this step, and the cost is real: wasted tokens, inaccurate outputs, and hours spent manually fixing what the AI should have handled. This guide gives you a concrete, repeatable process for testing and refining prompts fast. Whether you're building complex workflows or just trying to get better results from daily queries, these steps will compress your iteration time from hours to minutes. Understanding what prompt engineering actually is and how it works gives you the foundation; this article gives you the speed.
Key Takeaways
- Always establish a baseline prompt before making any changes to measure improvement.
- Test one variable at a time so you know exactly what caused the difference.
- Use structured evaluation criteria instead of gut feelings to judge AI responses.
- Keep a prompt log to track versions, results, and what worked or failed.
- Batch your refinements into short, focused sessions rather than sporadic edits over days.
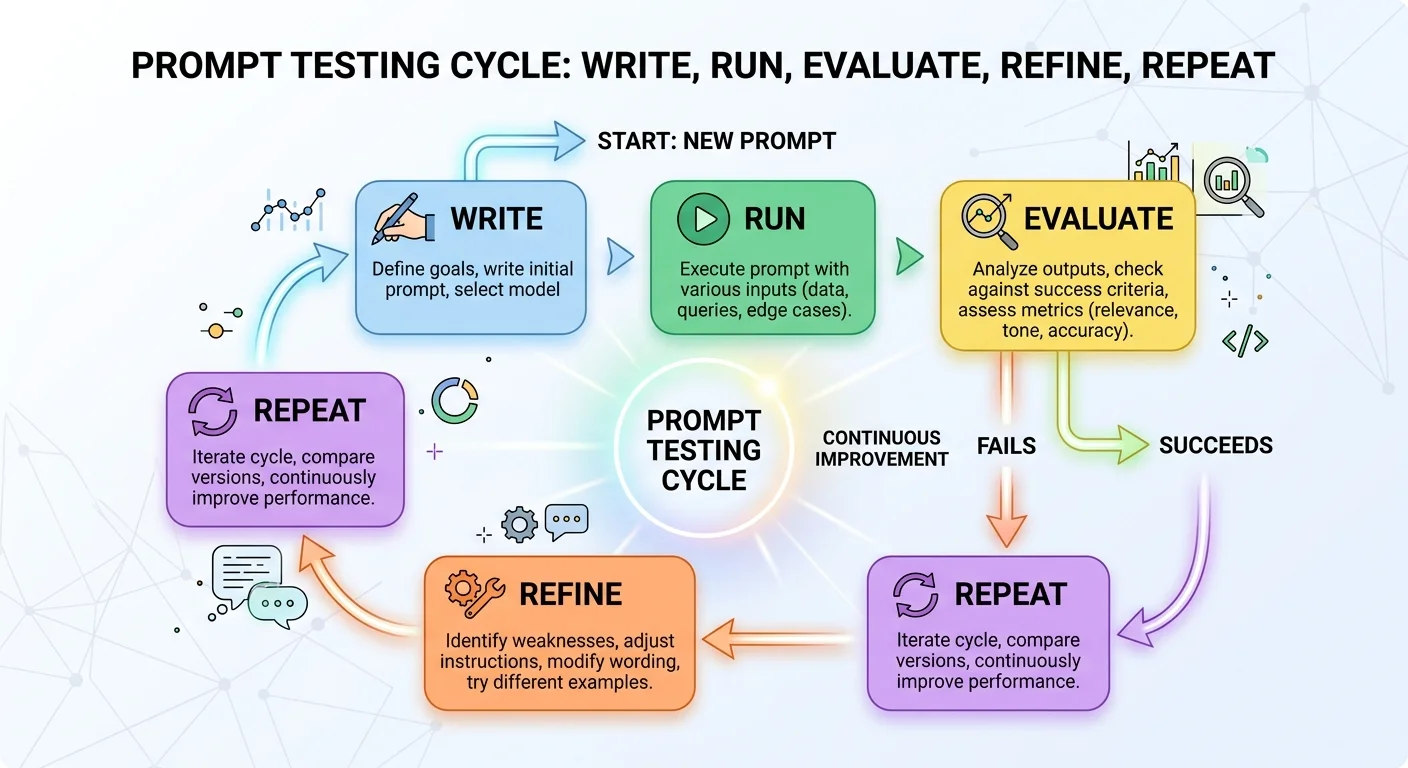
Step 1: Establish a Baseline Prompt and Evaluation Criteria
Before you touch a single word in your prompt, you need a reference point. Run your current prompt exactly as written and save the output. This is your baseline. Without it, every change you make is untethered, and you have no way to know whether version two is actually better than version one or just different. Too many users fall into the trap of constantly rewriting prompts without comparing results systematically.
Your baseline should be tested against the same task at least two or three times. AI models like ChatGPT are non-deterministic, meaning the same prompt can yield different outputs on each run. By collecting multiple baseline responses, you get a realistic picture of your prompt's performance range rather than a single cherry-picked example. This small extra step saves enormous confusion later.
Define Your Success Metrics
What does "good" look like for your specific use case? For some tasks, accuracy is everything. For others, tone, format, or completeness matters more. Write down three to five specific criteria before you begin testing. For example, if you're generating product descriptions, your criteria might be: correct specifications, persuasive tone, under 150 words, and include a call to action. Understanding how prompt clarity improves AI response quality makes defining these metrics much easier.
Write your evaluation criteria before your first test run, not after you've seen the output.
Anchoring your evaluation to explicit criteria eliminates the "this feels better" problem. Subjective judgment is unreliable when you're comparing eight slightly different versions of the same prompt. You need something concrete to point to. Even a simple checklist with yes/no items is better than relying on intuition. This discipline separates casual users from people who consistently get excellent results from AI tools.
Step 2: Isolate and Test One Variable at a Time
Here is where most people go wrong. They rewrite half the prompt, change the tone instruction, add three new constraints, and swap the output format all at once. When the result improves (or gets worse), they have no idea which change caused the shift. Effective prompt refinement works like a scientific experiment: change one thing, measure the impact, then decide whether to keep it. This approach feels slower, but it's actually much faster because you avoid dead ends.
Read also: How AI Voice Cloning Works in Video Narration Tools
Common Variables Worth Testing
The most impactful variables to test are role assignment, output format, specificity of instructions, and constraint language. For instance, adding "You are an experienced copywriter" to the beginning of a prompt often produces noticeably different results than a bare instruction. Similarly, specifying "respond in bullet points" versus "respond in a short paragraph" changes not just the format but the density and focus of the content. Each of these is worth testing independently.
When working with structured prompts, such as JSON-based prompts for AI agents, isolating variables becomes even more important. A single misplaced key or conflicting instruction in a structured prompt can derail the entire output. Test the structure separately from the content instructions. Run the skeleton first, then layer in constraints one by one. This methodical approach sounds tedious, but experienced prompt engineers know it cuts total refinement time in half.
One practical technique is to keep a "control" version of your prompt that you never modify. Copy it, make your single change to the copy, and run both. Compare the outputs side by side. If the new version clearly wins on your evaluation criteria, the copy becomes your new control. If it's a wash or a regression, discard the change and try a different variable. This is how professional prompt engineering differs from casual prompt writing in practice.
Step 3: Evaluate Outputs with a Scoring Framework
Once you have outputs from multiple prompt variations, you need a structured way to compare them. Reading through each response and picking the one that "feels right" does not scale, and it introduces bias. You'll naturally favor the most recent output or the one that matches your expectations, not necessarily the one that best serves your actual objective. A scoring framework forces objectivity.
Build a Simple Scoring Rubric
Create a rubric with your success criteria as rows and a 1 to 5 scale as columns. Score each output against every criterion independently, then sum the scores. The prompt version with the highest total score wins. This sounds overly formal for prompt testing, but it takes less than two minutes per output and prevents you from going in circles. Here is an example rubric for a content-generation prompt.
| Criterion | 1 (Poor) | 3 (Adequate) | 5 (Excellent) |
|---|---|---|---|
| Factual accuracy | Multiple errors | Mostly correct | Fully accurate |
| Tone match | Wrong register | Acceptable tone | Perfect match |
| Completeness | Missing key points | Covers basics | Thorough coverage |
| Format compliance | Ignores instructions | Partially follows | Exact format |
| Conciseness | Bloated or rambling | Some filler | Tight and focused |
Score each criterion before moving to the next output to reduce anchoring bias from previous versions.
After scoring three or four prompt versions, patterns emerge quickly. You might discover that adding a word count constraint consistently improves conciseness scores but slightly hurts completeness. That's valuable data. It tells you there's a trade-off to manage, and you can adjust accordingly. Without the rubric, this kind of insight stays invisible, buried under vague feelings of "that one was pretty good."
"The prompt that scores highest on your rubric is rarely the one that felt best during testing."
For power users who are new to structured evaluation, the principles behind this approach connect directly to concepts covered in beginner-level ChatGPT prompt guides, but applied with more rigor. Even simple prompts benefit from scoring. The point is not to overcomplicate things; it's to replace subjective impressions with reliable data. Once you've scored ten or fifteen prompt variations, you develop an instinct for what works that no amount of reading can provide.
Step 4: Iterate Rapidly and Document Everything
Speed matters in prompt refinement, but not at the expense of tracking your changes. The fastest way to iterate is in focused sessions: set aside 20 to 30 minutes, run five to eight variations, score each one, and pick a winner. This concentrated approach works far better than tweaking a prompt once in the morning, forgetting what you changed, and trying again after lunch. Batch your refinement work and treat it as a distinct task.
Maintain a Prompt Version Log
Every prompt version should be logged with the exact text, the date, the variable you changed, and your scoring results. A simple spreadsheet works fine. This log becomes your most valuable asset over time because patterns compound. After refining ten or twenty different prompts, you'll notice that certain techniques (like specifying output length or adding negative constraints such as "do not include disclaimers") consistently improve scores across tasks. Without a log, you rediscover these insights from scratch every time.
Prompt logs are especially valuable when working in teams, as they prevent duplicate testing and preserve institutional knowledge.
Your log should also capture failed experiments. Knowing that a particular phrasing consistently reduces accuracy is just as useful as knowing what improves it. Many power users only save their "winning" prompts, which means they waste time retesting approaches they've already proven don't work. A complete log, including dead ends, is a faster path to quality prompts than a curated collection of successes.
As you build experience, you'll develop personal templates and reusable components. A strong role assignment, a reliable format instruction, or a constraint clause that works across multiple domains. These become your prompt engineering toolkit. The refinement process gets faster with each project because you're not starting from zero; you're starting from a tested, documented foundation. That compound advantage is what separates someone who uses AI tools from someone who truly gets results from them.
Never delete old prompt versions, even if they performed poorly. Your logs lose diagnostic value without the full history.
Frequently Asked Questions
?How many baseline runs should I collect before changing a prompt?
?Is a simple checklist scoring rubric enough or do I need something complex?
?How long does a proper prompt refinement cycle actually take?
?What's the biggest mistake people make when rewriting AI prompts?
Final Thoughts
Testing and refining AI prompts doesn't require fancy tools or deep technical knowledge. It requires discipline: a baseline, isolated variables, a scoring framework, and a version log. These four steps, practiced consistently, will improve your prompt quality faster than any hack or template collection.
The compounding effect of documented refinement is real. Every test you run and record makes the next one faster and more precise, turning prompt writing from guesswork into a repeatable skill.
Disclaimer: Portions of this content may have been generated using AI tools to enhance clarity and brevity. While reviewed by a human, independent verification is encouraged.


